Automação com xPath: Utilizando Índices – Parte 3/6
SVLabs
21/09/2023
Tempo de leitura: 3minutos
Um dos desafios que encontramos em algumas páginas web, que desejamos automatizar, é a identificação de um elemento da forma mais precisa possível, mais em alguns casos esta localização fica comprometida por conta da impossibilidade de encontrarmos identificadores únicos na página para o elemento em questão.
É muito comum, em alguns sites de página única, acharmos 2 formulários com, exatamente, todos os elementos iguais, por ser uma prática muito usada objetivando o reaproveitamento de código, a cópia do código gerando até mesmo a repetição de ID’s.
Embora por regra não deva existir dois ID’s na mesma página, não raro encontramos esta situação. Justamente o ID que deve ser o identificador mais seguro, nesta situação acaba necessitando de um ajuste a mais.
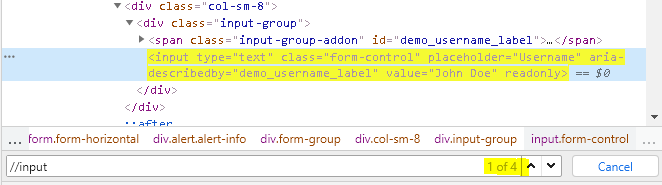
Desta forma, uma vez que temos dois ID’s na página, para diferenciar um do outro utilizamos um índice. Os índices começam em 1 e identificam o elemento pela ordem que é exibido nos “nós” do HTML.
Assim sendo, podemos utilizar um xPath da seguinte forma “(//*[id= ‘name’])[1] ” onde número que está no colchete é o índice do elemento, ou seja, é o primeiro elemento com ID name.
Em qualquer circunstância em que, mesmo depois de aplicado um endereço de xPath consistente, ainda temos mais de um elemento, podemos lançar mão do índice para garantir que o xPath criado aponta única e exclusivamente para um só elemento.
Exemplificando:
Fazendo a busca pelo texto input temos 8 resultados
Quando altero para o elemento input então a quantidade cai para 4 resultados
Quando aprimoro o xPath e insiro o atributo type = text então temos 3 resultados
Por fim, inserimos o nosso xPath dentro de parênteses e então aplicamos o índice 3 para obtermos o nosso elemento único, neste momento estamos gerando uma automação forte.
Vale lembrar que a força da automação vem da perfeita localização do elemento dentro da página, então fazer a verificação do xPath na inspeção dos elementos é o primeiro passo antes de aplicar este xPath à automação.